 PMAの構築 1 (パターンマッチング)
(paizaランク B 相当)
PMAの構築 1 (パターンマッチング)
(paizaランク B 相当)
問題にチャレンジして、ユーザー同士で解答を教え合ったり、コードを公開してみよう!
シェア用URL:
ツイートする
問題
 下記の問題をプログラミングしてみよう!
下記の問題をプログラミングしてみよう!
これまでの問題ではパターン (表れるかを判定したい文字列) が1つの場合の PMA の構築を行いました。
この PMA を用いることでパターンマッチングがおこなえるようになります。
パターンを "abab", テキスト (パターンが表れるかを判定したい文字列)を "abaabab" とした場合を例に説明します。
まず、PMA は次の図のようになります。図中の、ラベルとして文字が振られている黒い辺はトライ木の構築時にできた辺 (文字に対する遷移)、青い辺は failure で、赤い頂点は「パターンを受理する」頂点でした。
パターンマッチングの際にはテキストを 1 文字ずつ読み込み PMA の頂点を遷移していきます。 このときの動作を簡単に説明すると 次の (1), (2) の動作を 1 文字読み込む度におこなうことになります。
(1) 今いる頂点に読み込んだ文字の遷移が定義されていないなら、failureを用いてその文字での遷移が定義されている頂点まで遷移する
(2) 今いる頂点には読み込んだ文字での遷移が定義されているでそれを使って遷移する
このとき、根には全ての文字に対する遷移が定義されている必要があります。
例えば上に示したパターンマッチングの手順において、根にいる状態で 'b' という文字を読み込んだ場合の処理は未定義となってしまいます。
ここではもとのトライ木において根からの遷移が定義されていない全ての文字の遷移は根での自己ループとします。
上に示した PMA の場合、 'a' での遷移はすでに定義されているので、それ以外の文字 ('b', 'c', 'x' など) に対して新しく遷移を定義します。PMA は次の図のようになります。
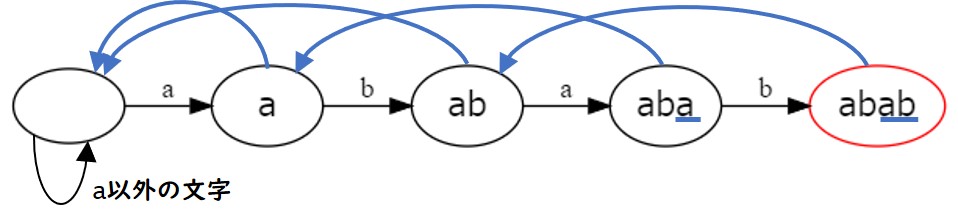
ここで PMA の性質として次の 2 つが成り立っていることを確認します。
(a) PMA の各頂点の対応する文字列は現在照合中の文字列を表す
(b) failure による遷移は照合中の文字列の長さを短くする
性質 (a) を確認するため、上の PMA を用いてテキスト "abaabab" でパターンマッチングをおこないます。このとき PMA 上を次の表のように移動しています。テキストの 1~3 文字目までを読み込ませた場合、頂点 aba に移動します(②)。その後、テキストの 4 文字目 'a' を読み込ませます。今いる頂点 aba には 'a' による遷移が定義されていないため、failure で頂点 a に遷移します(③)。頂点 a にも 'a' による遷移が定義されていないのでさらに failure で遷移をおこないます。根には 'a' による遷移が定義されていて、この遷移によって頂点 a へと遷移します(④)。

表の②ではトライ木の辺による遷移をおこなった結果、照合箇所が増えています。照合箇所がパターン "abab" の接頭辞であることを示しています(つまり、パターンが含まれている可能性があります)。表の③では
failure による遷移をおこなった結果、照合箇所の左端が右方向に進み照合中の文字列が短くなっています。これが性質 (b) に対応するもので、PMA 構築時の failure の「今の頂点の文字列の接尾辞に向かって引く」という引き方によるものです。また、この観察からパターンマッチングの際の計算量を知ることが出来ます。
テキストの文字数を L とします。照合箇所の左端、右端は必ず右方向に移動し、左端が右端を超えることはありません。ここから、照合箇所は尺取り法のように振舞うことが分かります。つまり、照合箇所の左端、右端はそれぞれ必ずテキストの文字数以下、両方合わせても最大で 2L 回しか移動しません。
このことからパターンが 1 つの場合のパターンマッチングを O(L) でおこなうことが出来ると言えます。
ここからは具体的な実装をおこないます。
AhoCorasick クラスに次のようなメンバ関数 match(text: string): bool を追加してください。 このメンバ関数はパターンが含まれるかを調べたい文字列
text に対して PMA を用いたマッチングを実行し、text にパターンが含まれるならば true、含まれないならば false を返します。match(string text) は次のような処理をおこないます。各変数の説明
・text の何文字目を見ているかを示す変数 i=1 とする.
・text の長さは L (0 < L) で, そのi文字目を text[i] とする.
・今いる頂点を表す変数 ptr の初期値を root とする.
実際の動作
while i ≦ Lの間
while ptrからtext[i]の文字を持つ辺が伸びていないとき
ptr = ptrからfailureで移動した先の頂点に更新
ptrをptrからtext[i]の文字を持つ辺で移動した頂点に更新
if ptrのis_patternがtrue
trueを返す
i = i+1とする
falseを返す
入力としてパターンとする文字列 S が与えられます。
その後、N 個の文字列 T_1, ..., T_N が与えられます。
各 T_i (1 ≦ i ≦ N) に対して S が連続部分文字列として含まれるかを判定してください。
含まれる場合には
Yes、含まれないならば No を出力してください。
- 入力される値
-
S
N
T_1
...
T_N
・1 行目では文字列 S が与えられます。
・2 行目では T の個数 N が与えられます。
・続く N 行のうち、i 行目では i 番目の文字列 T_i が与えられます。
入力値最終行の末尾に改行が1つ入ります。
文字列は標準入力から渡されます。 標準入力からの値取得方法はこちらをご確認ください
- 期待する出力
i 行目には T_i に対して S が含まれるかの判定結果を 1 行で出力してください。
末尾に改行を入れ、余計な文字、空行を含んではいけません。
- 条件
-
すべてのテストケースにおいて, 以下の条件をみたします
・1 ≦ N ≦ 100
・S, T_i (1 ≦ i ≦ N) は英小文字で構成される
・1 ≦ |S|, |T_i| ≦ 200 (1 ≦ i ≦ N, |S| は、S の文字数です。)
- 入力例1
-
abab
3
abaabab
abcd
ababab
- 出力例1
-
Yes
No
Yes
- 入力例2
-
abc
4
abcdef
aaabc
ababcd
aaaaccc
- 出力例2
-
Yes
Yes
Yes
No
- 入力例3
-
aaaa
3
aaa
bbbb
aaaaa
- 出力例3
-
No
No
Yes
